

The chip runs language models on small devices. It speeds up processing, cuts power use, and removes the need to send data to cloud servers.
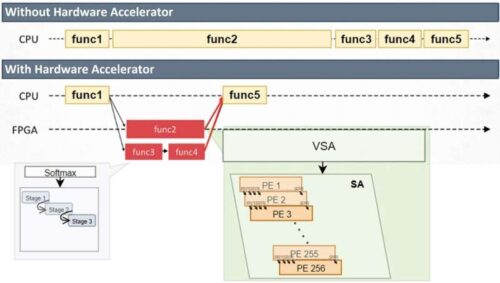
Researchers at Sejong University have developed the Scalable Transformer Accelerator Unit (STAU), a hardware solution that brings large language models (LLMs) like BERT and GPT to embedded systems. These models typically rely on cloud-based servers due to their heavy computational needs, but STAU makes it possible to run them directly on small devices. By adapting to different input sizes and model types, STAU supports real-time, on-device AI tasks with greater efficiency.
In tests, STAU achieved up to a 5.18× speedup over CPU-only processing and maintained over 97% accuracy. It also reduced total computation time by more than 68% on longer inputs, making it well-suited for AI applications on mobile devices, wearables, and edge systems—where speed, privacy, and low power consumption are key.
STAU is powered by a Variable Systolic Array (VSA) architecture, which handles matrix operations—the main workload in transformer models—by processing data row by row while loading weights in parallel. This approach reduces memory bottlenecks and increases processing speed, especially for LLMs with varying sentence lengths.
To improve hardware efficiency further, the team redesigned the softmax function, a step that usually slows down processing due to its use of exponentiation and normalization. They replaced it with a Radix-2 method that uses only shift-and-add operations, lowering hardware complexity without sacrificing result quality.
The researchers also introduced a custom 16-bit floating-point format tailored for transformer operations. This simplified format removes the need for layer normalization, another slow point in transformer models, and helps streamline the entire data pipeline.
STAU was implemented on a Xilinx FPGA (VMK180) and is controlled by an embedded Arm Cortex-R5 processor. This setup enables support for multiple transformer models—including those used in LLMs—through simple software updates, without needing hardware modifications.
By addressing both computation and memory challenges, the Sejong University team sees STAU as a step toward making powerful language models practical for devices at the edge, where real-time performance and data privacy are critical.