Nobody starts a software project expecting it to fail. And yet, the numbers tell a different story. According to McKinsey, large IT projects overrun their budgets by 45% on average. Just one in every 200 IT projects actually meets its goals on time, on budget, and with the scope originally promised. Those figures are not anomalies. They are the norm.
The frustrating part? Most of these failures are not caused by problems that were impossible to foresee. They happen because risks were either ignored, underestimated, or discovered too late to address without serious damage. Poor planning, communication gaps, and scope that quietly doubled over six months are behind far more project disasters than any technical complexity ever was.
That is what makes risk mitigation so valuable. Not as a checklist exercise, but as a genuine operating habit. Whether you are managing an internal development team or working with a provider of custom software development services in USA, the teams that consistently ship on time are not the luckiest ones. They are the most prepared.
This guide covers the most common software development risks, what causes them, and the strategies that actually reduce their impact before they turn into expensive problems.
What Is Risk Mitigation in Software Development?
At its core, risk mitigation is about not being surprised by the things you could have seen coming.
More formally, it refers to the process of identifying threats to a project, evaluating how likely they are and how badly they could hurt the outcome, and then doing something about it before the damage is done. The “doing something about it” part is where most teams fall short. Risks get logged in a spreadsheet during kickoff and then forgotten until the sprint where everything goes sideways.
There are four legitimate responses to any identified risk:
Avoidance means changing your approach to eliminate the risk entirely. If a particular third-party integration carries too much uncertainty, you find an alternative before writing any dependent code.
Mitigation means reducing either the probability of the risk occurring or the severity of the fallout if it does. This is the most common response and the heart of what most risk management frameworks focus on.
Transfer means shifting the financial or operational consequence to someone else, often through contracts, insurance, or service-level agreements with vendors.
Acceptance means acknowledging a risk and deciding to proceed anyway, typically because the probability is low, the impact is manageable, or the cost of addressing it outweighs the benefit. Acceptance is a valid choice when made consciously. It becomes a problem when it happens by default because nobody looked.
In practice, a well-run software project uses all four responses across different risks simultaneously.
Why So Many Software Projects Still Fail
It is tempting to think that with all the tools, methodologies, and project management frameworks available today, software project failure rates should be declining. They are not.
Research from the Standish Group found that 66% of technology projects still end in partial or total failure. BCG found that nearly half of all organizations saw more than 30% of their tech projects suffer delays or budget overruns. Harvard Business Review points out that one in six IT projects becomes a true disaster, with cost overruns exceeding 200% of the original estimate and schedule delays pushing 70%.
Here is what is most instructive, though: the causes are almost never technical. According to PMI, 56% of project failures trace back to poor communication. Unrealistic deadlines account for another 25%. A lack of skilled team members contributes to 29%. Poor project management overall is the root cause in 47% of failures.
Put simply, software projects fail because of people problems and process problems, not because the technology was too hard. Which means most of these failures were preventable.
The Most Common Risks in Software Development
1. Scope Creep
Ask anyone who has managed a software project for more than a few months and they will tell you that scope creep is the quiet killer. It rarely shows up as one dramatic demand. It is the product manager who asks for “just one more filter” on a dashboard. It is the stakeholder who mentions in passing that they assumed the mobile version would be included. It is the feature added after the design is approved, the integration tacked on mid-sprint, the requirements that keep shifting because nobody documented the original agreement clearly enough.
The result is a project that ends up costing 30 to 50% more than planned and taking significantly longer to deliver. Changing requirements are a contributing factor in nearly 43% of software project overruns.
The fix is not complicated, but it does require discipline. Document the project scope before a single line of code gets written. Get formal sign-off from every stakeholder who has the authority to request changes later. Then create a change request process that forces any new requirement through an honest evaluation of its budget and timeline impact before it gets approved. Agile methodologies help here because scope is broken into sprint-sized commitments. Additions become visible, negotiable, and traceable rather than quietly accumulating in the background.
2. Poor Requirements Management
Vague requirements are a tax that the development team pays in rework and the business pays in missed expectations. When the technical team builds what they understood and the stakeholder expected something entirely different, someone has to absorb that cost, and it is rarely the person who wrote the ambiguous brief.
Mismanagement of requirements contributes to 32% of project failures, which is a significant share for a problem that a better discovery process could largely prevent.
The approach that works is straightforward: invest real time upfront. Before any code is written, run a thorough discovery phase where wireframes, prototypes, and user stories translate business goals into something both sides can actually review and critique. The gap between what a stakeholder describes verbally and what a developer interprets technically is often enormous. Prototypes close that gap early and cheaply. Fixing misunderstood requirements before development is a fraction of the cost of fixing them after.
Document everything, version it, and get sign-off. That paper trail is not bureaucracy. It is protection for everyone involved.
3. Unrealistic Timelines
Here is an uncomfortable truth about software deadlines: a significant share of them are set by people who are not responsible for meeting them. A launch gets tied to a marketing event. A release is promised to a client before the development team has estimated the work. A fiscal quarter ends and someone needs a deliverable to show. The business commits to a date and the engineering team inherits it.
A quarter of all software project failures trace back directly to unrealistic deadlines. When teams are forced to hit dates that were never grounded in technical reality, the consequences are predictable. Testing gets compressed. Edge cases get deferred. Code quality suffers. Developers burn out.
There is a better approach. Estimates should be built from historical project data, not optimism. Break projects into phases and estimate each one independently, since granular estimates are consistently more accurate than high-level guesses. Build a contingency buffer of at least 15 to 20% into every phase. And when a deadline genuinely cannot move, the conversation should shift to what gets de-scoped to hit it, not how the team works harder to fit everything in. That tradeoff needs to be documented and agreed upon by everyone who owns the outcome.
4. Technical Debt
Technical debt is what happens when speed is consistently prioritized over quality. Quick fixes instead of proper architecture. Skipped documentation. Code that works but nobody fully understands. Refactoring that keeps getting pushed to “next sprint” until it never happens at all.
It feels like a developer concern, but it is very much a business risk. McKinsey research suggests technical debt consumes more than 20% of a development team’s total capacity on average. That means roughly one day per week, every week, is spent managing the consequences of past shortcuts instead of building new value. The painful irony is that the pressure to move fast is usually what created the debt, and the debt is precisely what makes everything slower going forward.
The practical fix is to treat debt reduction as a required deliverable rather than optional cleanup. Enforce coding standards through code reviews. Set aside dedicated sprint time for refactoring. Track technical debt as a formal backlog item with an estimated cost, so it appears in leadership conversations as a business risk rather than just a developer grievance. Companies that follow these systematic practices report 40% fewer software defects across the development lifecycle.
5. Security Vulnerabilities
Security risks differ from most other project risks in one important way: when they materialize, they tend to be both expensive and very public. A data breach is not just a technical incident. It is a business event with regulatory, reputational, and financial consequences that can follow a company for years.
Target is a well-known example. Third-party vendor access was underestimated as a risk, and the resulting breach cost the company far more than any proactive security investment would have required. This is not a story unique to Target. According to Verizon’s 2024 Data Breach Investigations Report, third-party involvement in security breaches doubled from 15% to 30% in a single year, making vendor and integration security one of the most pressing concerns for any software project today. Source
The most effective approach is to build security into the development process from day one rather than treating it as a final gate before launch. This is what practitioners call a “shift left” approach, and the evidence for its effectiveness is strong. Run regular penetration testing and automated vulnerability scans throughout development, not just at the end. Make security an explicit item in every code review. Enforce strict access controls on third-party integrations from the outset, with periodic reassessments as the project evolves.
6. Resource Constraints and Team Capability Gaps
Software development is as knowledge-intensive as any discipline gets. A team’s capabilities are not just about headcount. They are about the specific skills a project requires at each stage, and whether the people available actually have those skills. PMI research shows that 29% of project failures are directly linked to a lack of competent team members. Almost half of CIOs acknowledge their teams are already managing more projects than they can realistically handle.
Beyond raw skills, there is the hidden cost of turnover. Replacing a software developer can cost more than 100% of their annual salary once you factor in recruiting, onboarding, and the productivity gap while a replacement gets up to speed. Knowledge silos make it worse. When critical understanding lives entirely in one person’s head, a resignation or illness can become a project crisis practically overnight.
This is why many businesses choose to work with an established Software development company in USA rather than scaling an in-house team under tight timelines, particularly when a project requires specialized skills that are difficult to hire for quickly. Whether you build internally or partner externally, the mitigation principle is the same: run a capability audit before the project starts, close skill gaps before they become blockers, and build knowledge-sharing habits such as documentation, pair programming, and cross-training into your regular workflow.
7. Third-Party and Integration Risks
Very few software products are built from scratch in isolation anymore. They connect to payment gateways, CRM systems, analytics platforms, third-party APIs, and legacy infrastructure. Every one of those connections is a dependency your team does not fully control.
When a vendor changes their API without adequate notice, deprecates a feature, or experiences an outage, your project absorbs the impact. This is not hypothetical. It happens regularly, and teams that have not planned for it find themselves scrambling under the worst possible conditions.
Map your external dependencies early and assess the risk profile of each one honestly. What happens if this service goes down? What happens if this API changes? Prioritize integrations with providers who have strong SLAs and transparent versioning policies. Build abstraction layers in your codebase so that third-party dependencies are isolated, meaning a vendor change does not cascade into a complete rewrite. And always maintain fallback behavior for any integration that is critical to core functionality.
8. Poor Communication and Stakeholder Alignment
Of all the risks on this list, poor communication is the one that shows up in project failure post-mortems most consistently. PMI attributes 56% of project failures to communication breakdowns. BCG found that misalignment between technical and business teams ranks among the top three root causes of IT project failures globally.
What makes communication risk particularly tricky is that it is invisible until it is not. The project appears to be moving. Standups are happening. Updates are going out. But the business stakeholders believe the project is on track to deliver one thing, and the development team is building something subtly different. By the time the gap surfaces, it is usually too late to correct without significant cost.
Solving this requires structure, not just goodwill. Build a communication plan at the start of every project that defines who receives what information, how often, and through which channel. Hold regular cross-functional reviews that put technical and business stakeholders in the same room looking at the same data. Use dashboards that give everyone real-time visibility into project status, open risks, and active blockers, rather than polished reports that can obscure what is actually happening on the ground.
A Practical Framework for Managing Risk Across the Project Lifecycle
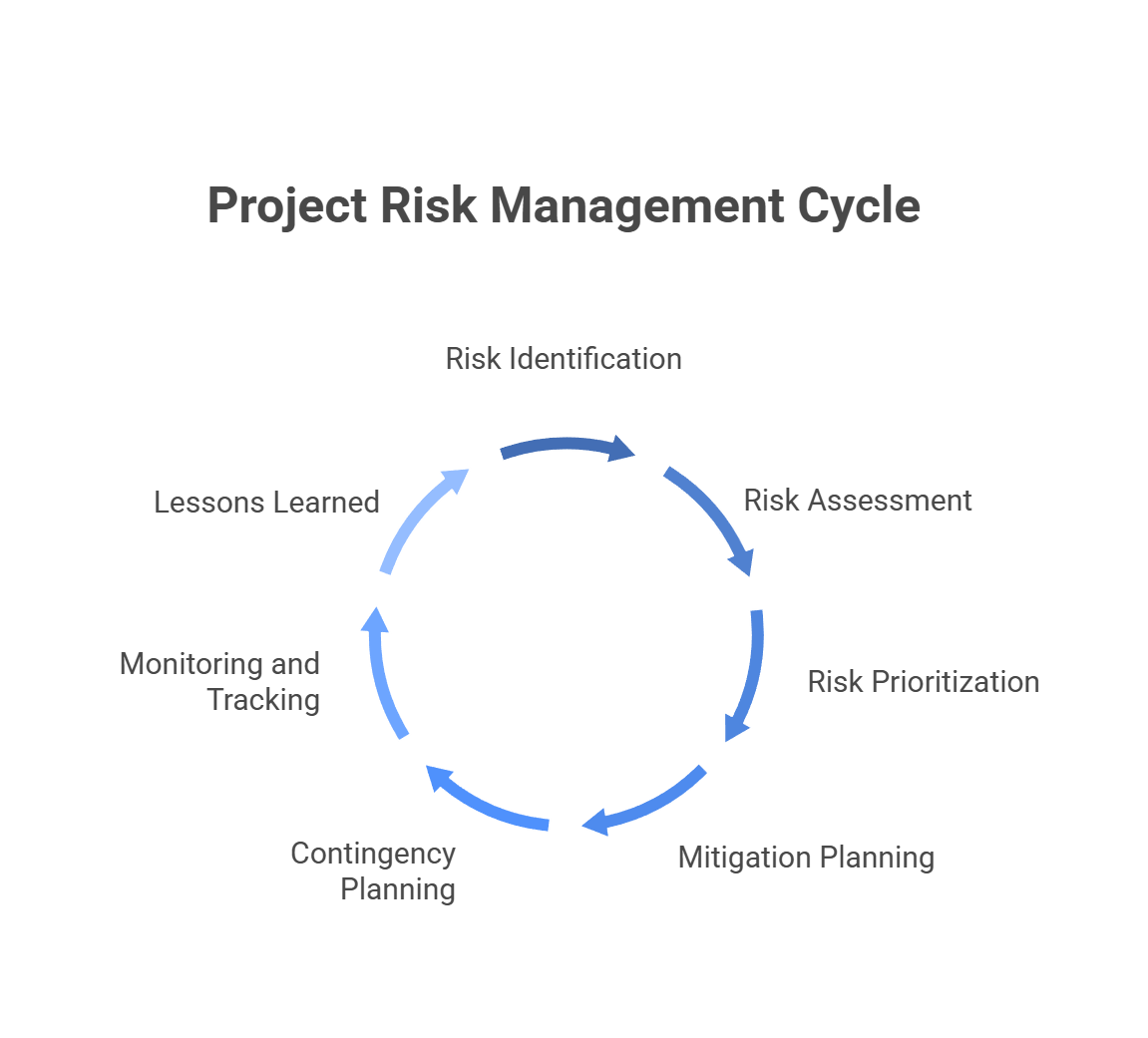
Knowing what can go wrong is useful. Having a repeatable process for catching it early is what separates teams that deliver consistently from those that are perpetually in crisis mode. Here is the seven-step framework high-performing software teams use:
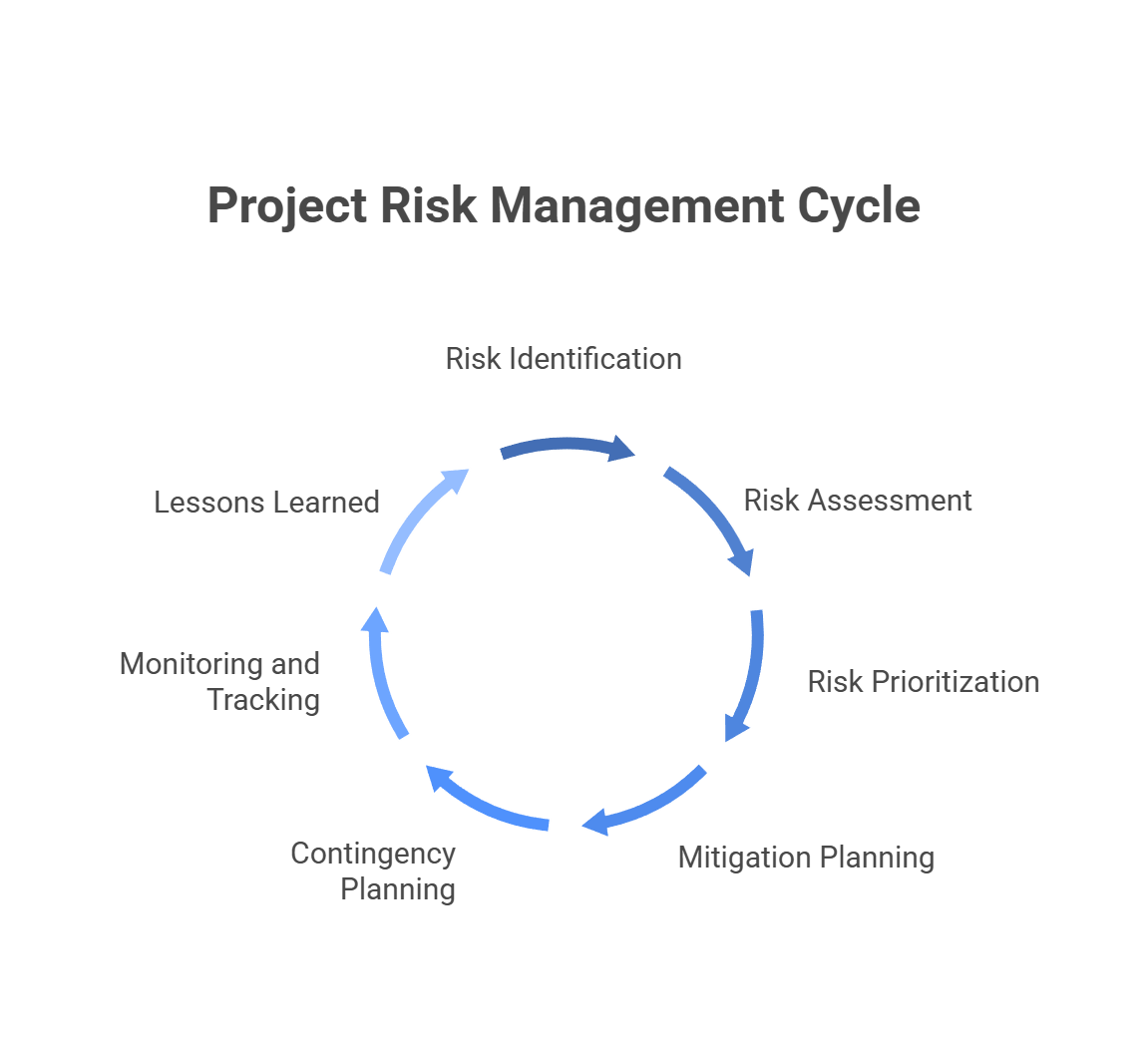
Step 1:
Risk Identification. Before work begins, run a structured session with the full team to surface every potential threat across technical, organizational, and external dimensions. This is not the time to filter by likelihood. The goal is to get everything on the table.
Step 2:
Risk Assessment. For each identified risk, estimate two things independently: how likely is it to occur, and how badly would it hurt if it did? A simple high, medium, or low rating for each is enough to work with. The combination determines where attention should go.
Step 3:
Risk Prioritization. Work the high-probability, high-impact risks first. Low-probability, low-impact risks can be monitored passively. The common mistake is treating every risk as equally urgent and spreading attention thin across all of them.
Step 4:
Mitigation Planning. For each priority risk, define a specific plan. What action reduces the likelihood? What limits the damage if it happens anyway? Who owns the execution? Vague plans do not get executed.
Step 5:
Contingency Planning. Some risks cannot be fully mitigated. For those, you need a response ready before the risk materializes, not while you are in the middle of dealing with it. Who makes the call? What gets paused? What are the escalation paths?
Step 6:
Monitoring and Tracking. Assign a risk owner for every significant risk and review the register at every sprint retrospective or project checkpoint. Risks are not static. New ones appear as projects evolve, and old ones either resolve or change character over time.
Step 7:
Lessons Learned. When the project closes, document what actually happened. Which risks materialized? Which mitigations worked? What would you do differently? This kind of institutional memory is rare, which is exactly why teams that build it consistently outperform those that do not.
Does Agile Actually Help With Risk Management?
There is a lot of enthusiasm in the industry about Agile solving project risk problems. The reality is more nuanced. BCG research found no consistent correlation between agile adoption and project success when it is implemented without the underlying cultural and operational changes that make it work. Calling sprints “Agile” while running waterfall-style decisions underneath does not move the needle.
That said, when Agile is practiced with genuine discipline, it creates real structural advantages for risk management. Short delivery cycles mean problems surface in weeks rather than months. Regular stakeholder reviews reduce the risk of building in the wrong direction for extended periods. Retrospectives create a standing forum for teams to flag what is not working before it becomes a project-level crisis.
The key word is discipline. The teams that get real risk management value from Agile are the ones running tight sprints, maintaining a visible and prioritized backlog, and holding honest retrospectives rather than performative ones.
How Technology Is Changing the Risk Management Picture
The risk management software market was valued at $15 billion in 2024 and is projected to grow at roughly 12% per year as projects grow more complex and organizations invest in earlier warning systems.
At the leading edge, companies like Meta are using AI-powered tools such as their Diff Risk Score system to predict whether specific code changes are likely to trigger production incidents before they go live. In 2024, Meta used this system to ship over 10,000 code changes during a single high-stakes event with minimal production impact. That is a meaningful demonstration of what AI-assisted risk management looks like at scale.
For most teams, the wins are less exotic but equally valuable. Automated testing pipelines catch defects before they reach production. Continuous integration tools surface conflicts between parallel development threads early. Project management platforms with built-in risk registers and dependency tracking give everyone a shared view of what is at risk and what is being done about it. None of these require a large research team to implement, and all of them meaningfully reduce the chance that small problems grow into large ones.
The Real Cost of Skipping Risk Management
There is often resistance to investing in risk management, particularly in early-stage companies or teams under pressure to ship fast. The perception is that it slows things down. The data says otherwise.
Teams with structured risk management practices finish projects with 28% fewer delays on average. They see 40% fewer software defects over the development lifecycle. They reduce cost overruns from an industry average of 27% down to around 8%. IT project failures collectively cost the U.S. economy between $50 billion and $150 billion in lost revenue and productivity every year. Organizations using proven project management practices waste 28 times less money than those operating without structured processes.
For businesses evaluating development partners, these numbers matter in a very practical way. Whether you are building an in-house team or engaging a custom web development company in USA, the risk management practices a partner has in place are one of the clearest predictors of whether your project will actually land. It is worth asking about them early in any engagement.
Risk mitigation is not overhead. For any team serious about delivering, it is one of the highest-return investments they can make.
Final Thoughts
Software development involves uncertainty. That is never going to change. Requirements shift, priorities get realigned mid-project, and teams face pressures that no planning document fully anticipates.
What separates the teams that navigate that uncertainty well from those that get buried by it is not raw talent or luck. It is the discipline to think through what could go wrong before it does, assign clear ownership to those risks, and build enough structure to respond quickly when things do not go as planned.
Start with the risks most likely to hit your current project. Build a response plan for each. Put the communication structures in place that keep every stakeholder genuinely informed rather than just technically updated. The goal was never a risk-free project. That does not exist. The goal is a team that knows how to adapt when the unexpected shows up, and one that does not have to reinvent the wheel every time it does.
The difference between a project that succeeds and one that falls apart is rarely the technology. It is almost always the preparation behind it.