There is a quiet frustration building inside a lot of companies right now.
They have experimented with AI, built prototypes, and in many cases shipped something that looks impressive in a demo. And yet, when it comes time to rely on it, to put it in front of customers, or to trust it inside real workflows, things start to break.
At the inaugural York IE AIConf in Ahmedabad, Ashish Patel, Senior Principal Architect for AI, ML & Data Science at Oracle, put words to what many teams are experiencing: “Demos are easy. Reliability is hard.”
That line captures the gap between experimentation and execution, and it points to a deeper truth. AI does not fail because the models are not good enough. It fails because the systems around them are not.
The 90/10 Trap
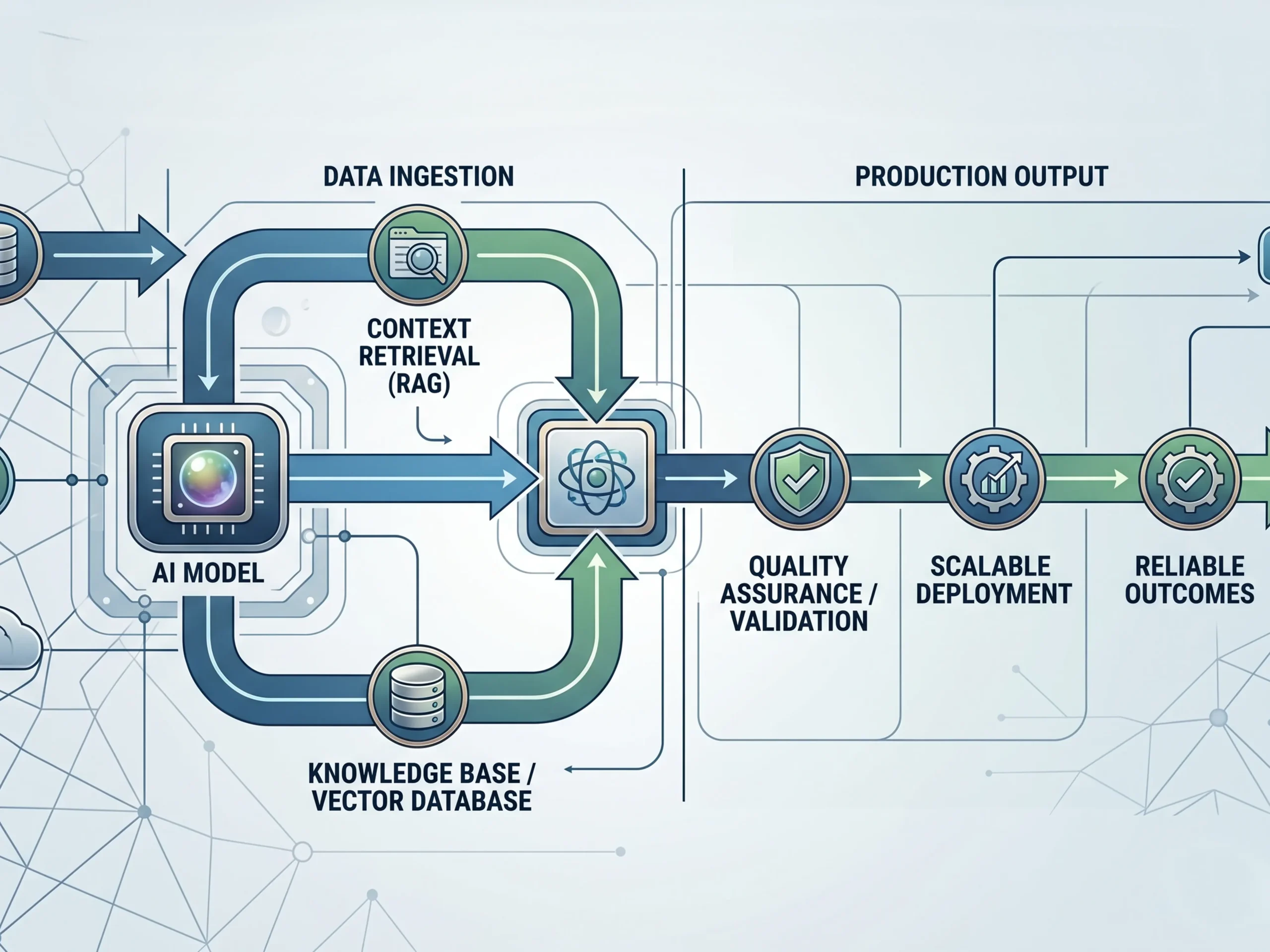
Most teams fall into what Ashish described as the 90/10 trap. Ninety percent of the effort goes into building something that works in a controlled environment, while the final ten percent, the part that makes it reliable, scalable, and production ready, is where things begin to unravel.
The issue is not intelligence. It is structured. Static workflows break when they encounter edge cases, and systems often lack memory, error handling, and proper tool integration. What looks like a smart system in a demo quickly reveals itself to be fragile in the real world.
Even more importantly, teams tend to misdiagnose the problem. They assume the model is the bottleneck, when in reality, the bottleneck is the lack of system capabilities around it.
That insight shifts the conversation from model selection to system design. And that is where the real work begins.
Why Better Models Don’t Fix the Problem
If the model is not the bottleneck, then what is? The answer is context.
There is a common belief that better models produce better outcomes. It feels intuitive. Bigger models, more training data, and more intelligence should lead to better answers. But in practice, performance is not driven by intelligence alone. It is driven by how well the system informs that intelligence.
As Ashish explained, a model’s output is only as reliable as the specific, up to date data provided in the prompt. Without context, even the most advanced models fail in simple ways. They do not understand your business, your data, or your constraints, so they fill in the gaps. And they do it convincingly.
This is why so many teams struggle with accuracy. They invest in fine tuning, prompt engineering, and new tools, when the real issue is that the system is not providing grounded, relevant information. Ashish offered a practical rule that cuts through the noise: use RAG first. Ninety percent of agentic failures are context related, not behavior related.
That means your retrieval layer matters more than your model choice. Data quality and accessibility are not backend concerns. They are the foundation of performance.
Hallucination Is a Design Problem
This also reframes one of the most talked about challenges in AI: hallucination.
Most teams treat hallucination like a glitch, something that occasionally happens and needs to be caught after the fact. But that framing misses the point. Garbage in, garbage out. Wrong context leads to wrong output.
Models are designed to be helpful. When they lack information, they fill in the gaps with plausible answers. They are not malfunctioning. They are operating exactly as designed. The failure is in the system that surrounds them.
There are three patterns that show up consistently. First, poor context, where the system cannot retrieve the right information. Second, no validation layer, where outputs are never checked before being used. And third, weak architecture, where there is no redundancy or second opinion built in.
Fixing hallucination is not about writing better prompts. It is about building better systems through stronger retrieval, built in validation, and structures that allow outputs to be tested before they are trusted.
From One Agent to Many
As teams begin to address these challenges, the architecture naturally evolves. Most start with a simple idea: build one powerful AI agent that can handle everything. It is a logical starting point, but it quickly becomes limiting.
As tasks grow more complex, a single agent runs into cognitive overload. It is responsible for too much context, too many decisions, and too many responsibilities at once. As that load increases, accuracy drops and errors become more frequent.
The solution is not to build a smarter single agent. It is to build a system of agents.
In a multi agent architecture, each agent has a defined role. One researches, another analyzes, another executes, and another reviews. Instead of one generalist trying to do everything, you create a team of specialists. This structure introduces something most AI systems lack today: verification.
As Ashish noted, in a multi agent setup, one agent can double check the work of another. One agent produces an output, another critiques it, and a third synthesizes the result. The system becomes more reliable not because any single model is perfect, but because the system is designed to catch mistakes.
This is the shift from isolated intelligence to coordinated intelligence, and from outputs to outcomes.
What Actually Separates Systems That Work
By the end of the session, the distinction became clear. There are two types of AI systems being built today.
The first are experimental. They are impressive in demos but brittle in production, relying on prompts, linear workflows, and best case assumptions. The second are structured. They are designed for real world conditions, incorporating memory, retrieval, validation, orchestration, and resilience.
These systems are built to recover when something breaks, not just to work when everything goes right. That is the difference between building something that looks like AI and building something that actually works.
The Bottom Line
AI is not just a model problem. It is a systems problem.
The teams that win in this next phase will not be the ones chasing the latest model release. They will be the ones investing in architecture, context, retrieval, validation, and coordination. They will move beyond demos and build for reliability.
Because in the end, the goal is not to create something that looks intelligent. It is to create something that can be trusted. And that only happens when the system is designed to support it.
To stay up-to-date on all upcoming York IE events, follow us on LinkedIn.