Architecture diagrams lie, a little. Not on purpose. They show boxes and arrows in clean arrangements and make everything look sequential and tidy. What they cannot show is what fails first, what surprised you, and which decisions you would fight hardest to keep if someone wanted to simplify things.
This is about those decisions.
The goal was to move reference data from an on-premises MongoDB instance, the registered golden source for enterprise reference data, into a governed cloud pipeline, with Athena as the query surface and an enterprise Data Marketplace as the publication layer. Straightforward enough in theory. The complications were in the details, as they always are.
Why Three Layers and Not One
The obvious path is: extract from MongoDB, put it somewhere in the cloud, let people query it. You can make that work, technically. What you end up with is a storage location that everyone gradually stops trusting, because it is never clear whether what is in it reflects the current state of the source or a snapshot from two weeks ago, and the schema is whatever the last person who ran the extraction thought was sensible.
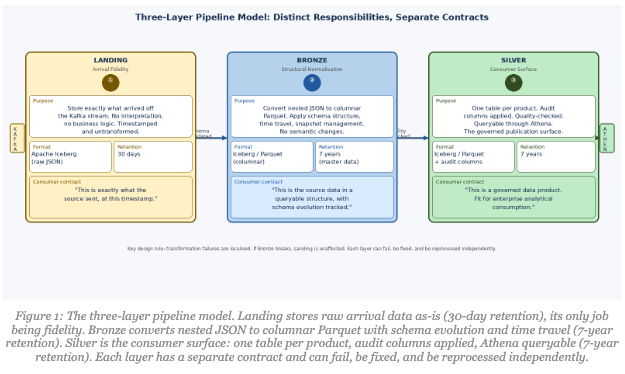
Three explicit layers, Landing, Bronze, Silver were a direct answer to that. Each has a distinct responsibility, a different file format, a different retention policy, and a different contract with the data.
Landing stores exactly what came off the Kafka stream: raw JSON, timestamped, untransformed, held in Apache Iceberg tables with a 30-day archive policy. No business logic, no interpretation. When something goes wrong downstream, you can go back to Landing and know with confidence it reflects what was in the source at that point in time. Thirty days covers any incident investigation cycle while keeping storage costs reasonable.
Bronze takes Landing’s raw data and establishes actual table structure, converting nested JSON to columnar Parquet format in Iceberg tables, with proper snapshots, schema evolution, and time travel capability. The archive policy steps up to seven years for master data, reflecting the regulatory context we operate in. Bronze is its own stage rather than being collapsed into Landing because you want transformation failures to be visible and localised. If Bronze breaks, Landing is unaffected. You can fix the issue and reprocess without touching the arrival checkpoint.
Silver is what consumers see. Shaped for analytical use, mandatory audit columns applied, quality-checked, queryable through Athena, stored as Parquet in Iceberg with seven-year retention. This is the product surface, and it needs to be held to a different standard than the intermediate layers. Blurring Bronze and Silver into one layer is a shortcut that makes debugging a nightmare.
What the Kafka Layer Actually Does
People describe Kafka as “the streaming layer” and move on. The decisions inside the Kafka Connect configuration were where a lot of the pipeline’s trustworthiness was actually built.

Two mechanisms ran in parallel inside Kafka Connect, and both were essential.
Dead Letter Queue for operational visibility. When a message failed, whether due to a malformed payload, type mismatch, or unexpected nesting, it went to a DLQ with a configurable retention period rather than being silently dropped or blocking the stream. The DLQ was what turned “we noticed something was wrong three days later” into “we got alerted within twenty minutes and had the bad events right there to inspect.” The difference between those two outcomes is significant in any environment, but especially so when downstream teams treat the data as authoritative.
Schema validation via a Schema Registry. Every event goes through schema validation before reaching the S3 sink. If a source-side change altered field names or types, the pipeline rejected the event at Kafka rather than writing garbage into Landing. Quiet corruption is the worst kind of data problem, because you often do not find out until a consumer’s job breaks in production on a Friday afternoon. Early rejection trades a visible failure in a controlled place for a hidden failure discovered much later.
Together, those two things meant Landing could be treated as a trustworthy checkpoint rather than a dump of whatever came down the stream.
Two Transformation Stages, Two Different Jobs
Worth being precise about something here, because it is easy to give the wrong impression. We are working with reference data from an authoritative golden source. The business requirement explicitly stated that no business-logic transformation would be applied. This is a one-to-one mapping from source to destination. We are not enriching, aggregating, or deriving anything. The value proposition is faithful preservation.
But “no transformation” does not mean “no work.” MongoDB stores nested JSON documents. Analytical consumers need flat columns in Parquet. Getting from one to the other is structural conversion, not semantic transformation, but it is still a non-trivial pipeline stage that can fail.

Stage 1: Landing to Bronze. The job takes raw JSON from the landing path, flattens nested sub-documents into a columnar structure, deduplicates by key, and writes the result as Parquet into an Iceberg table. A checksum validation confirms everything that left MongoDB arrived. No business semantics touched, no values changed. Structural conversion only.
Stage 2: Bronze to Silver. A single MongoDB collection often holds multiple logical entity types: country codes, currency codes, organisational role types, all in one collection because that is convenient for the operational system. For consumers, that is a mess. The Bronze-to-Silver stage splits each collection by data class into its own table. One product, one table. Governance becomes tractable because you can draw a boundary around each product.
Every Silver table gets a standard set of audit columns at this stage: CREATE_DATE_TIME, UPDATE_DATE_TIME, VALID_FROM and VALID_TO (distinguishing current from historical values), DELETE_FLAG (soft delete from the source system), CREATED_BY, UPDATED_BY, SOURCE_SYSTEM, JOB_NAME, JOB_RUN_ID, JOB_START_DTTM, and JOB_END_DTTM. More on why these matter shortly.
Keeping these as separate pipeline stages means each one can fail, be fixed, and be rerun independently. That matters more at 2am than any architectural elegance argument.
CDC: Not the Easy Part
Change data capture gets described like a solved problem. Extract the changes, apply them downstream, done. What it actually gives you is events. The tricky parts are what you do with them: deduplication when events arrive out of order, applying deletes correctly via soft-delete flags rather than hard deletes, making sure a record that changed five times in an hour arrives downstream in the right final state.
The pipeline captures inserts, updates, and deletes from MongoDB and applies them accurately to the target, validating the change order to guarantee events are consumed in the correct sequence. After the initial full data load, all subsequent synchronization runs through CDC only, no reprocessing of the full dataset. The pipeline runs on a monthly batch cadence: the 5th of every month at 07:00 UTC, fully automated, no dependency on working days or holiday calendars.
The issue that generated the most support tickets, somewhat embarrassingly, was the absence of events. If nothing changed in MongoDB, nothing flows through the pipeline. That is correct behaviour, entirely aligned with how CDC works. But teams expecting a daily file drop as confirmation the pipeline was alive read “no new file” as “something is broken.” We built an explicit no-change signal: a small indicator that the pipeline ran, checked, found nothing new, and is healthy. Not glamorous engineering. It closed a significant number of unnecessary incidents.
Minimal Transformation Is Not Minimal Responsibility
Because we were publishing authoritative reference data without enrichment, some stakeholders assumed the quality bar would be lighter. The logic was: we are not changing much, so there is less to get wrong.
The opposite is true. When the value proposition is “we preserved the truth accurately,” validation is what proves you did that. The quality gates work in layers. Schema validation at Kafka is the first gate: a schema mismatch fails the job and alerts the reference data owner team. Basic data quality checks follow: non-null enforcement for mandatory fields, allowed value validation for reference codes. Reconciliation runs between layers, record counts, null rates, key distributions, so any drift between Landing, Bronze, and Silver surfaces quickly. Checksum logic at Landing confirms everything that left MongoDB actually arrived. When twenty-one products all make the same promise, the validation proving that promise has to be airtight.
What Audit Columns Actually Do
I used to think of audit columns as compliance decoration. Then I watched a team spend three days on what turned out to be a simple question: was this Silver record stale, soft-deleted, or just unchanged since the last run?
With the audit columns in place, that is a five-minute query. VALID_FROM and VALID_TO tell you whether you are looking at a current or historical value. DELETE_FLAG tells you if the source system soft-deleted the record. JOB_RUN_ID and JOB_START_DTTM tell you exactly which pipeline run produced the record. SOURCE_SYSTEM confirms provenance.
Without them, it is a three-day archaeology project involving Airflow logs, Kafka offsets, and escalating frustration. The pattern repeated across multiple incidents. Not dramatic data corruption, just the ordinary operational questions that come up constantly when data is shared across teams. Audit columns turn those questions from investigations into lookups.
What Made This a Platform Rather Than Just a Pipeline
A pipeline gets data from A to B. A platform is something people can build on without needing to understand all the plumbing underneath.
The difference was the Data Marketplace and what it forced. The endpoint for a finished product is not “the Silver table exists.” It is “the product is listed in the Marketplace with metadata, a Kitemark quality score, documentation, and subscription behaviour.” Compliance with all active standards at deployment time is mandatory. Consumption occurs exclusively via the Marketplace subscription model. Not a suggestion. An enforced constraint.
That enforcement is what makes naming conventions matter in practice rather than in principle. A consumer searching for a dataset finds it using enterprise-standard terminology, not the internal shorthand that made sense to the team that built it. The metadata framework transition to FDM mapping is unglamorous work. It is also what makes the catalogue actually navigable.
The pipeline earned trust by being predictable. Schema validated. Bad events quarantined in the DLQ. JSON structurally converted to Parquet. Data classes partitioned into individual tables. Audit columns consistently applied. Products published with documentation. Consumers querying through Athena and subscribing through the Marketplace. Nothing surprising.
In a large enterprise, nothing surprising is the goal.